
2024-11-12 09:30
科技记者报道,佐治亚理工学院的Jeffrey Skolnick团队近日发表论文,探讨了深度学习在预测抗体-抗原相互作用中的应用。研究聚焦于SARS-CoV-2刺突蛋白受体结合域(RBD)的抗体预测,采用了深度学习模型AF2Complex。通过两项基准测试,评估了模型预测抗体-抗原复合物结构的准确性,及其在混合抗体库中识别特定抗原结合抗体的能力。结果显示,结合多种输入序列比对策略,AF2Complex在61%的案例中成功生成了显著的预测,并取得了47%的成功率。此外,模型还能以高精确度区分结合RBD的抗体和随机抗体,展示了深度学习在免疫疗法开发和生物过程理解中的潜力。然而,RBD的结构复杂性和糖基化修饰仍对预测构成一定挑战。

2024-11-12 09:30
科技大师David Baker获2024年诺贝尔化学奖,他在蛋白质设计领域发表700余篇论文,引用量超17.7万。除学术界卓越成就外,他还创办或参与21家公司,其中AI制药企业Xaira Therapeutics获10亿美元融资。Baker的成长从对哲学转向生物学的兴趣开始,他开发的Rosetta软件成为蛋白质结构预测领域的佼佼者,并通过Rosetta@home和Foldit项目集合全球力量,推动科学进步。尽管面临AlphaFold2的竞争,Baker团队继续以开源方式贡献于蛋白质科学的发展。

2024-11-12 09:30
科技记者提炼要点: 谷歌、苹果等机构研究人员发现,大模型内部编码的正确答案远比实际表现的多,但仍可能输出错误内容,此现象被称为“大模型幻觉”。新研究揭示,这种幻觉与模型内部特定token的真实性信息编码有关。研究人员通过分析这些token,发现大模型知道的比表现出来的更多,且内部表征可预测模型可能犯的错误类型。这一发现有助于未来开发针对性解决方案,提高错误检测性能。然而,错误检测器的泛化能力有限,表明真实性编码并非统一,而是具有多方面性。此外,研究还涉及了错误类型的调查和预测,以及内部真实性与外部行为的一致性问题。

2024-11-12 09:30
科技记者报道,上海人工智能实验室等联合提出即插即用的SearchLVLMs框架,该框架可无缝整合多模态大模型,通过互联网检索增强,使大模型无需微调即可对实时信息准确反馈。研究团队还提出数据生成框架UDK-VQA,自动生成依赖实时信息的视觉问答数据。实验显示,配备SearchLVLMs的模型在回答准确率上超过自带检索增强的GPT-4o模型35%,显著提升开源和闭源模型对实时信息的反馈能力。

2024-11-12 09:30
OpenAI的下一代旗舰模型“猎户座”被曝提升幅度不及预期,相比GPT-4到GPT-3的飞跃,其改进已进入收益递减阶段。此消息引发业界关注,有学者担忧AI行业高估值建立在模型能力不断增强的预期上,改进放慢可能导致金融泡沫破灭。同时,其他AI公司如Anthropic和谷歌也面临类似瓶颈。OpenAI CEO在采访中仍对AGI表示兴奋,称研究路径已清晰,但人才流动和外界质疑仍存。
2024-11-12 09:30
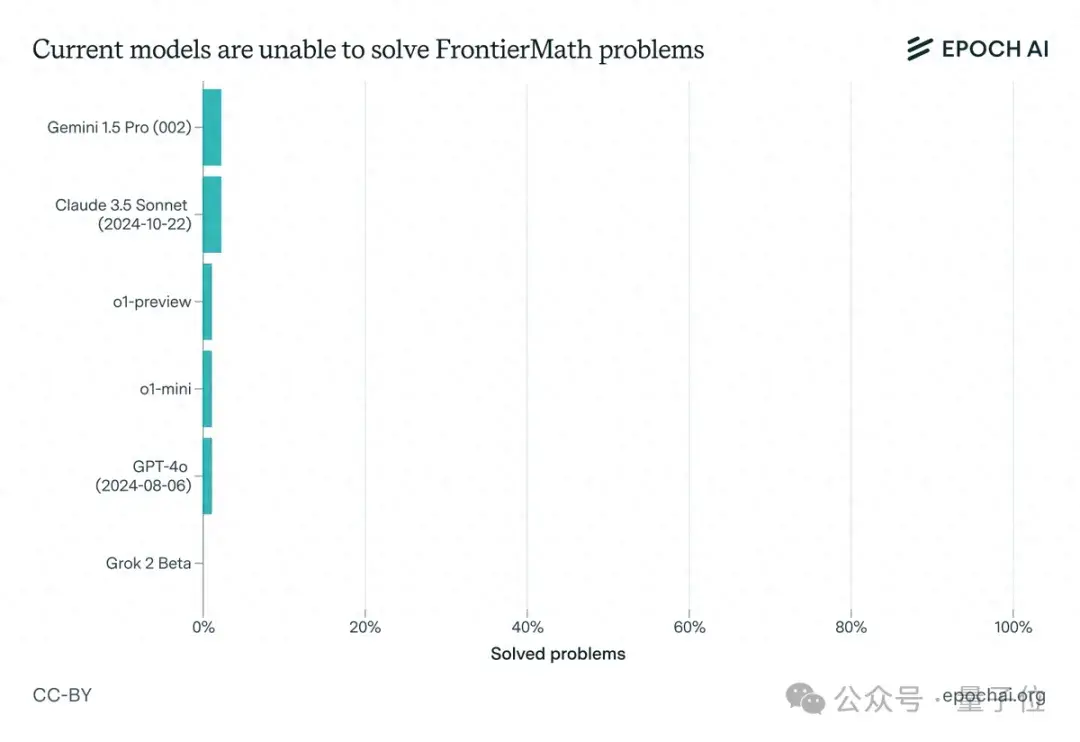
科技记者报道,2024年11月11日消息,由非营利研究机构Epoch AI联合60多位顶尖数学家,包括菲尔兹奖得主陶哲轩等,共同提出了一个名为FrontierMath的新数学基准。该基准旨在评估AI的高级数学推理能力,包含数百道原创且难度颇高的数学题,涵盖现代数学多个主要分支。此前,大模型们在各种数学benchmark上表现优异,然而面对FrontierMath,包括Claude 3.5 Sonnet、GPT-4o和Gemini 1.5 Pro等在内的一众顶尖大模型纷纷折戟,解题率均不足2%。数学家们表示,这些题目难度很高,大模型们需要数年时间才能攻克。同时,该机构计划持续推进这一基准,并定期评估大模型的表现,以观察其数学推理能力的提高情况。

2024-11-12 09:30
中科大MIRA实验室提出一种全新自动化知识图谱构建框架SAC-KG,该框架利用大语言模型(LLM)一键生成百万级领域知识图谱。SAC-KG通过结合领域语料和开放知识图谱,实现精准知识检索与自适应提示,有效提升知识图谱构建的准确率和领域特异性。相较于现有最先进方法,SAC-KG在使用ChatGPT作为基础模型时,准确率和领域特异性分别达89.32%和81.25%,提升效果显著。该研究已发表在CCF-A类人工智能顶级会议ACL 2024上。

2024-11-12 09:30
11月11日,字节跳动公布最新通用图像编辑模型SeedEdit,支持一句话轻松改图,包括修图、换装等各类编辑操作,已在豆包PC端及即梦网页端开启测试。该模型通过简单自然语言驱动编辑任意图像,是国内首个实现产品化的通用图像编辑模型。SeedEdit在通用性、可控性、高质量等方面取得突破,适用各类编辑任务,支持用户奇思妙想。相比业界同类方法,它取得显著更优性能,能理解模糊指令,执行细致编辑时具有更高图像保持率和成功率。未来,SeedEdit将在真实图片保真、编辑精确性等方面进一步优化,提升用户体验,支持更高效创作。

2024-11-12 09:30
科技巨头OpenAI面临大模型发展瓶颈,转换策略以应对。研究显示,若保持当前发展势头,大数据储量预计在2028年耗尽,大模型发展可能放缓。OpenAI的下一代旗舰模型Orion质量提升有限,引发关于AI发展是否将放缓的争议。OpenAI内部人士透露,公司已成立基础团队研究训练数据匮乏问题,并转向训练后对模型进行改进,采用新技术如强化学习和人类反馈来提高模型性能。同时,OpenAI正在研究使用AI生成的数据进行训练,但可能带来模型相似性问题。这一策略转变凸显了AI领域对scaling laws极限的探索,以及应对数据短缺的新方法。

2024-11-12 09:30
AIxiv专栏是机器之心发布的学术技术内容栏目,已报道2000多篇全球高校与企业顶级实验室的内容,促进学术交流。该专栏介绍了马里兰大学吴曦旸和关天瑞等开发的AutoHallusion框架,可自动生成视觉大模型的幻觉案例,解决大模型幻觉研究中数据集缺乏问题。该框架通过操控场景物体构成创建与语言先验冲突的图像,设计问题探测大模型语言模块,触发幻觉。实验显示,GPT-4V等大模型在基准数据集上问答准确率最高仅66%。此研究有助于理解大模型幻觉机制,提升模型性能。

2024-11-12 09:30
科技巨头字节跳动最新推出了图像编辑模型SeedEdit,该模型主打一句话轻松P图,是国内首个产品化的通用图像编辑模型。用户只需使用简单的自然语言,就能实现换背景、转风格,或者在指定区域进行元素的增删和替换。SeedEdit精准理解复杂指令,支持中英文提示词,并能保持原图细节完整性。与业界其他方案相比,SeedEdit在通用性、可控性和高质量上实现新的突破。目前,该模型已在豆包PC端和字节AIGC平台即梦网页端开始测试。经过实测,SeedEdit展现出了极高的编辑精准度和丰富的玩法,让用户能够轻松实现各种创意编辑。与Dall・E 3、Midjourney等AI绘图平台相比,SeedEdit在编辑生图的质量和美感上有所提升,体验更佳。

2024-11-12 09:30
科技记者报道提炼: 今年的机器人学习顶会CoRL上,两篇杰出论文引领风潮。其中一篇由丰田研究院和美国伦斯勒理工学院团队提出的新方法,让自动驾驶汽车在极限操控条件下如漂移时,仍能安全可靠运行。该团队通过训练一个高性能的条件扩散模型,成功使丰田Supra和雷克萨斯LC 500实现自动漂移,为自动驾驶在紧急情况下的应用铺平道路。 另一篇杰出论文则来自艾伦人工智能研究所,他们通过强化学习训练了一个名为PoliFormer的导航智能体,该智能体在模拟环境中训练后,无需调整即可在现实世界中导航。PoliFormer在多项导航基准测试中取得领先成绩,展现了强大的泛化能力。 此外,还有四篇论文获得杰出论文提名,涉及模仿学习数据集优化、机器人策略泛化、人形机器人以及视觉语言动作大模型等领域。这些研究成果共同推动了机器人学习与技术的发展。

2024-11-12 09:30
清华大学龚海鹏团队提出了一套基于几何学习的模型套件GeoStab-suite,包含三个模型,分别预测蛋白质突变后的适应度、稳定性等指标。其中,GeoFitness模型使用深度突变扫描数据库进行训练,可预测所有单个突变的蛋白质变体适应度。该团队还利用GeoFitness的编码器开发了GeoDDG和GeoDTm两个模型,分别用于预测蛋白质突变后的稳定性变化。通过预训练策略与数据扩展,模型性能和通用性得到显著提高。在基准测试中,GeoDDG和GeoDTm的表现优于其他最先进方法。该研究成果已发表在《Nature Computational Science》上,并为蛋白质科学领域提供了有用的工具。

2024-11-12 09:30
11月11日,国家地方共建具身智能机器人创新中心公布一年建设成就,并宣布开源计划,推动具身智能技术落地。创新中心旨在打造涵盖技术开源、产学研协同、标准制定、应用示范等多方面的具身智能生态圈。总经理熊友军表示,将专注解决关键技术问题,创建繁荣的产业生态。目前,创新中心正加速技术突破,包括通用机器人平台“天工”和智能体平台“开物”。同时,创新中心与多家机构合作,共同打造具身智能开源社区,并牵头制定行业标准,已参与发布相关国家标准。此外,成立具身智能机器人俱乐部,推动公众接受度,并计划举办人形机器人马拉松比赛。创新中心将借助北京经开区优势,推动应用场景落地,持续完善具身智能生态圈。

2024-11-12 09:30
科技记者提炼要点: 清影迎来重要升级,推出10秒、4K、60帧超高清视频生成能力,支持任意尺寸与自带音效,显著提升人体动作与物理世界模拟。此次升级基于CogVideoX模型与音效模型CogSound。CogVideoX在数据筛选、模型结构、视频理解等方面创新,验证视频生成scaling law有效性,并开源部分模型。CogSound则能为无声视频增添动人音效,实现音视频语义高度一致。两项技术共同推动视频生成领域进步。

2024-05-28 00:00
科技记者报道: 在《5000天后的世界》一书中,凯文·凯利预测称雄增强现实(AR)的将不是目前的科技巨头GAFA(谷歌、苹果、脸书、亚马逊),而是新兴的创新者。历史表明,主导一个时代的企业往往无法在下一个时代继续领先,因为它们的成功成为创新的障碍。尽管谷歌在人工智能通用智能(AGI)领域投入巨大,但仍落后于OpenAI。OpenAI的GPT-4等强大模型的开发成功,揭示了大型科技公司创新不足的问题。 OpenAI的联合创始人兼总裁格雷格·布罗克曼在接受可汗学院CEO萨尔曼·可汗的采访时,揭示了OpenAI成功的秘诀。OpenAI的团队不仅拥有学术背景的研究人才,还有优秀的工程人才,这种组合使他们能够更有效地解决问题和推动项目进展。布罗克曼强调了研究与工程并重的方法,以及团队组织方式对于创新的重要性。 OpenAI的使命是建立造福人类的AGI,并已经在这一目标上工作了8年。团队致力于建立更大的神经网络,提高其能力、协调性和安全性,并部署这项技术以发挥其作用。布罗克曼认为,每一步进展都能真正产生影响,并开始造福人类。 面对人工智能的安全性问题,布罗ckman认为对AI持有复杂情感是正确的,既要对新事物感到惊奇,也要警惕潜在的陷阱。他提到,AI安全问题有着悠久的历史,而OpenAI在不断学习如何面对这些风险。 在教育领域,ChatGPT被视为一个工具,可以帮助无法获得优质教育资源的学生。布罗克man强调,制定规则和将技术融入教育需要广泛的意见和实践经验。 最后,布罗克man和可汗都认为人工智能将增强而非削弱人类能力,每个人都可以通过智能手机获得AI的“超能力”。乐观是推动OpenAI前进的关键因素。

2024-05-28 00:00
科技记者报道: 今年3月,人工智能领域的重要人物Mustafa Suleyman离开Inflection AI,加入微软领导其AI部门。微软在AI人才争夺战中胜出,而Inflection AI则面临领导层变动。Suleyman带领约70名团队成员转投微软,引发对Inflection AI未来影响的讨论。 Inflection AI已获得15.25亿美元融资,专注于开发具有情感共鸣的个人AI助理Pi。公司宣布由经验丰富的硅谷老将组成的新领导团队,包括新任CEO Sean White、CTO Vibhu Mittal、COO Ted Shelton和产品负责人Ian McCarthy。 微软支付近6.5亿美元给Inflection,其中6.2亿美元用于非独家技术许可,3000万美元用于避免诉讼。Inflection AI联合创始人Reid Hoffman表示公司资金充足,将在情感智能领域保持领先。 新团队致力于打造具有同理心的聊天机器人,专注于EQ(情感智能),与OpenAI、微软、谷歌等行业巨头竞争。Pi在EQ测试中表现出色,能够提供个性化和情感化的回应。 Inflection AI计划建立EQ的行业基准,并通过“移情微调”定制个性化模型。公司与企业合作,降低培训成本,并提供品牌特定的人工智能客服。

2024-05-28 00:00
科技记者摘要: 华中科技大学、华南理工大学及浙江大学的研究人员提出了一种新的文本识别方法VimTS,旨在提高跨领域文本端到端识别的泛化能力。该方法通过实现不同任务之间的协同作用,仅使用较少参数便有效地将原始的单任务模型转换为适合图像和视频场景的多任务模型。VimTS包括一个提示查询生成模块和一个任务感知适配器,两者共同促进不同任务之间的显式交互,并帮助模型动态地学习适合每个任务的特性。研究人员还提出了一个利用内容变形场(CoDeF)算法的合成视频文本数据集(VTD-368k),以更低的成本学习时间信息。实验结果显示,VimTS在多个跨域基准测试中超越了现有方法,包括图像到图像和图像到视频的识别任务。论文链接:https://arxiv.org/pdf/2404.19652,代码地址:https://vimtextspotter.github.io。

2024-05-28 00:00
科技记者报道:厦门大学与腾讯优图团队推出名为“领唱员(Cantor)”的多模态思维链架构,该架构无需额外训练即可显著提升性能。在ScienceQA数据集上,基于GPT-3.5的Cantor准确率达到82.39%,较传统思维链方法提升4.08%。在MathVista数据集上,Cantor的准确率比原始Gemini模型高出5.9%。Cantor架构通过结合视觉和文本信息,避免了决策幻觉,并通过专家模块提供高级推理信息。该架构的设计包括决策生成和执行两个步骤,并通过模块化执行和汇总执行来生成最终答案。Cantor的性能超越了微调方法,且已开源,相关论文已上传至arXiv。
2024-05-28 00:00
国产开源项目Sora迎来更新,全面支持国产AI算力,包括华为昇腾。此次更新包括了视频编辑功能,用户可以使用ReVideo进行视频编辑。该项目由北京大学和兔展团队联合开发,所有数据、代码和模型均已开源。Open-Sora-Plan在GitHub上获得10.4k颗星星,用户可以在抱抱脸上进行试玩。项目团队对Sora进行了版本迭代,采用了更高质量的视觉数据与caption,并优化了CausalVideoVAE的结构。最新版本Open-Sora-Plan v1.1.0展示了视频生成的能力,包括10秒和2秒的文本生成视频,以及视频编辑功能。团队还展示了失败案例,并提出了可能的解决方案。用户可以在Hugging Face上试玩,但需要注意的是,生成每个视频大约需要4-5分钟。背后的技术框架包括Video VAE、Denoising Diffusion Transformer和Condition Encoder。项目目前仍在训练和观察第三阶段的模型,预计将增加帧数至513帧,约合21秒的视频。与前作相比,最新版本在CausalVideoVAE结构和数据质量上进行了优化。