
Merge two images together with a prompt

ProteusV0.3: The Anime Update

Emojis on Stable Diffusion via Dreambooth
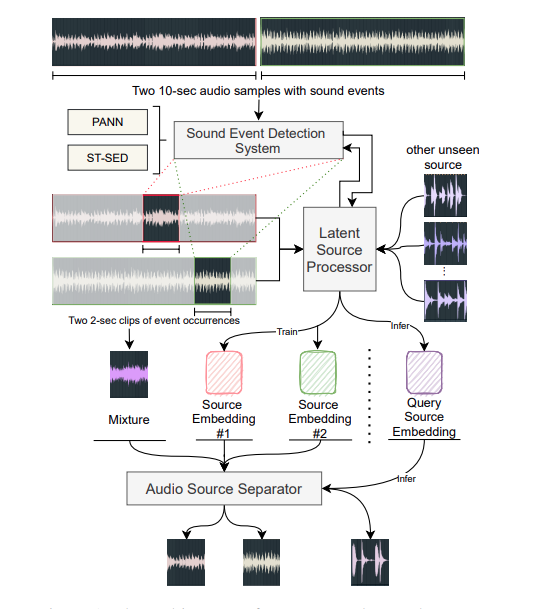
Zero shot Sound separation by arbitrary query samples

This model create picture with RealVisXL3 ( with WebUI api ).

Stable Diffusion 2.1 - Realistic Vision 5.1 - VAE

Neurogen Model for Splurge Art

An anime style

Implementation of SDXL RealVisXL_V1.0 img2img

Stable Audio Open is an open-source model optimized for generating short audio samples, sound effects, and production elements using text prompts.

Detect AI Generated Text with Fast-DetectGPT

a powerful and competitive model like Midjourney v6 and DALL-E 3 but Open and Decentralized

A fine-tuned SDXL LoRA trained on images of banksey street art

Llama2 13B with embedding output

trained on grateful dead posters.

Make realistic images of real people instantly (w/ ip-adapter-plus-face_sdxl_vit-h)

Image-Prompt Multi-view Diffusion for 3D Generation

Juggernaut Aftermath Model with original TRCVAE (Text2Img, Img2Img and Inpainting)

Dreamshaper superfast generation

Juggernaut XL v7 Model (Text2Img, Img2Img and Inpainting)
