
A fast high quality SD 1.5 model, Realistic Vision V6.0 B1 Hyper

Mistral-7B-v0.1 fine tuned for chat with the Dolphin dataset (an open-source implementation of Microsoft's Orca)

Open-Sora is a work-in-progress model.

Open diffusion model for high-quality video generation
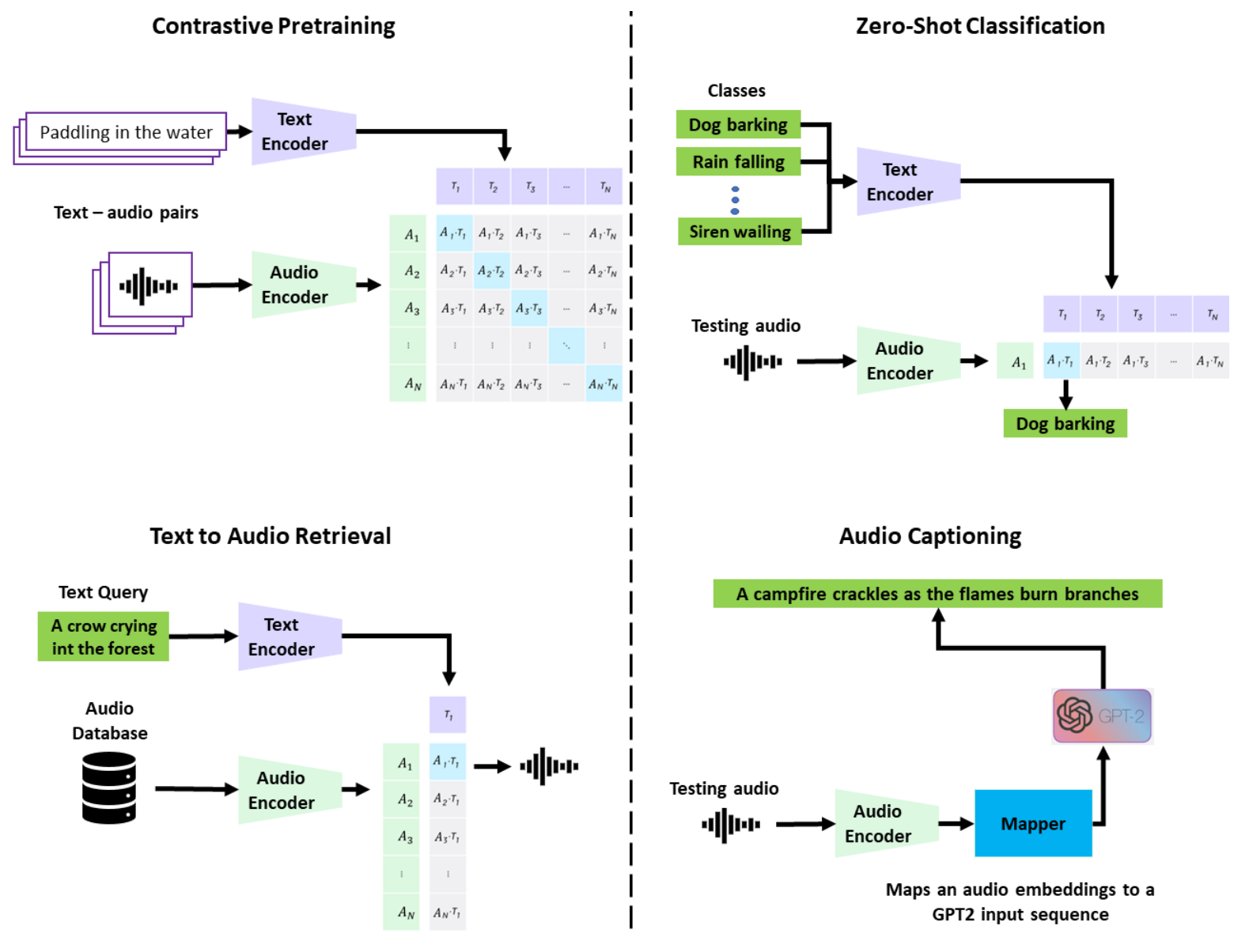
Caption an audio

Method for generating bizarre looking videos from a series of language descriptions of the video. From the Bot Intelligence Group at CMU: Peter Schaldenbrand, Zhixuan Liu, & Jean Oh

SDXL fine-tuned on pareidolia

MAGNeT: Masked Audio Generation using a Single Non-Autoregressive Transformer

Modify images with humans using pose detection

This is wizard-vicuna-13b trained with a subset of the dataset - responses that contained alignment / moralizing were removed

Fine-tuned SDXL on my favorite architectural photographer, Iwan Baan

Pixray with custom settings
A Visual Language Model for GUI Agents

ControlNet with SD 2.1

music label

Generate 3D assets using text descriptions

Edit images with human instructions

Video Smoother: AMT All-Pairs Multi-Field Transforms for Efficient Frame Interpolation

The image prompt adapter is designed to enable a pretrained text-to-image diffusion model to generate SDv1.5 images with an image prompt

human-like cat sdxl-lora model
