A large language model by EleutherAI

SDXL finetuned on fantasy TTRPG sourcebook art.

Unofficial Re-Trained AnimateAnyone (Image + DWPose Video → Animated Video of Image)
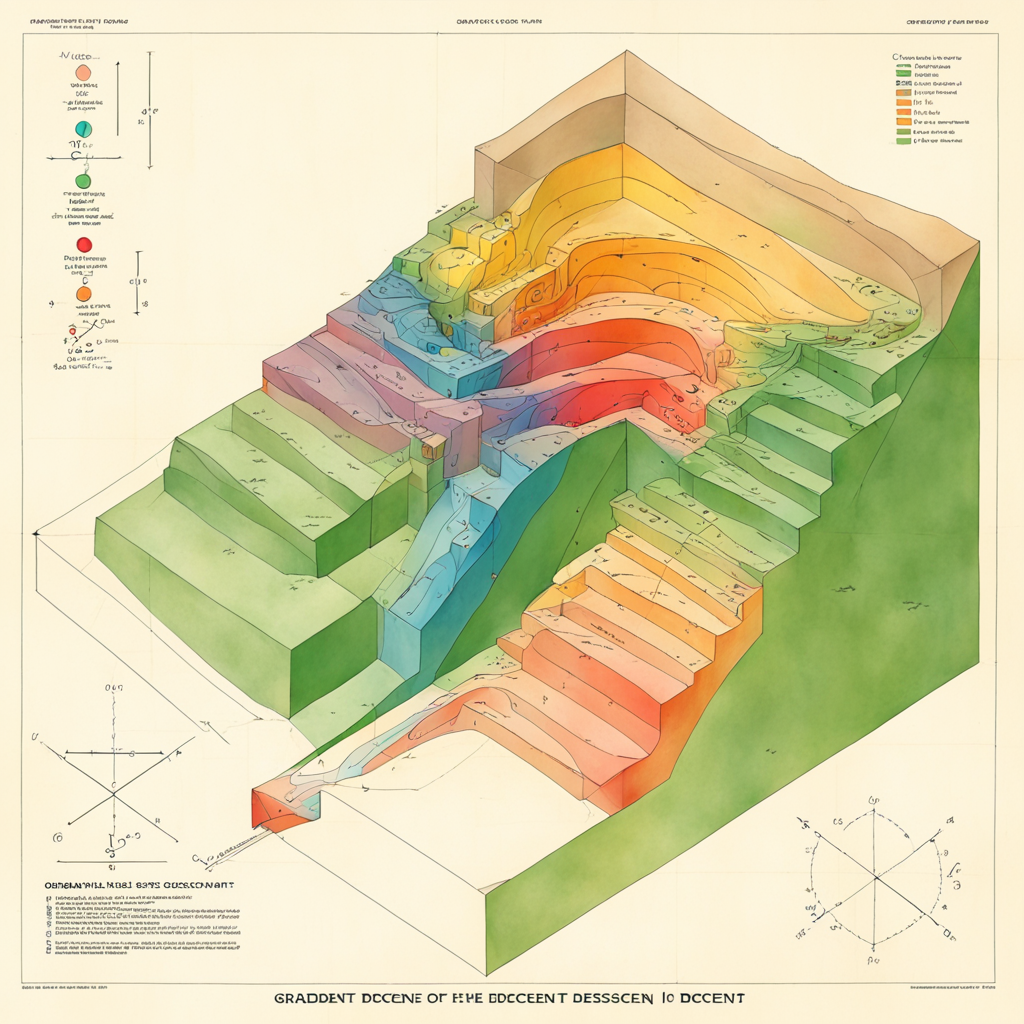
sdxl-isometric-geology is an SDXL fine-tune that's been trained with cool USGS isometric block and fence diagrams from the 1950s and 1960s.

Photos on Polaroid, including hands holding Polaroid photos

lmsys/vicuna-13b-v1.3

MusicGen trained on NewJeans

MusicGen fine-tuned on Lofi Gaming Beats. Prompt Prefix: "lofi gaming beats, low bpm"

Base version of Mamba 790M, a 790 million parameter state space language model

Stylized Audio-Driven Single Image Talking Face Animation

Seamlessly create stunning product shots by blending with inspirational references for a fresh, modern look

Transform your image or QR code like never before

Genetic algorithm like mixing of SDXL models

SDXL finetune to generate slick Icons and Flat Pop Constructivist Graphics with thick edges. Trained on Bing Generations

Arc2Face: A Foundation Model of Human Faces

Fork of https://replicate.com/schananas/grounded_sam that uses OwlV2 instead of Grounding Dino

Cut and Learn for unsupervised object detection and instance segmentation
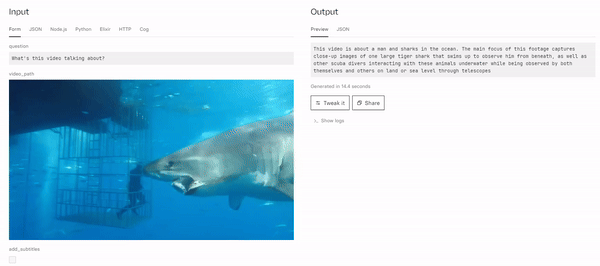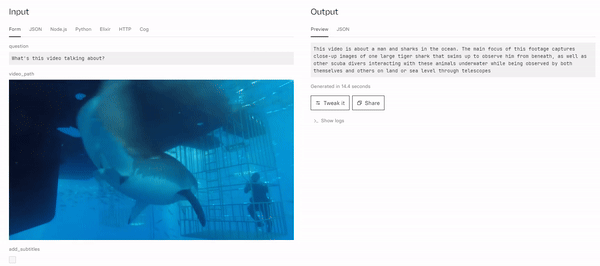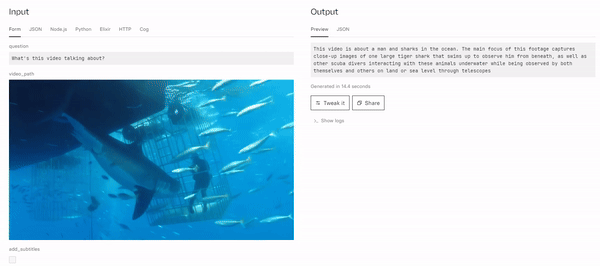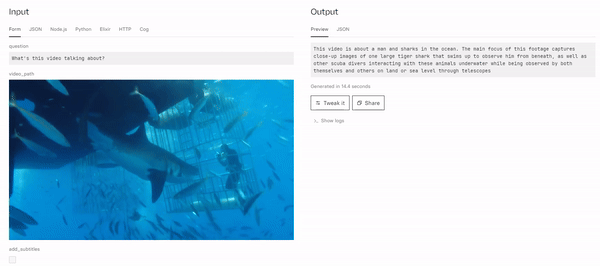
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens

Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild. This is the SUPIR-v0F model and does NOT use LLaVA-13b.

Open-Sora: Democratizing Efficient Video Production for All. This is the 16x512x512 video generation variant.
