
'''Last update: Now supports img2img.''' SDXL Canny controlnet with LoRA support.

album cover generator

Whisper-Large-V2 + Pyannote 3.0 diarization via WhisperX
An EfficientNet for music style classification by 400 styles from the Discogs taxonomy

Generate professional faceshots using Stable diffusion and roop

camcorgi generates photos that feature the cam corgi known as @corgi.cam

Deep3D: Real-Time end-to-end 2D-to-3D Video Conversion, based on deep learning

Du bear, baidu doll.

Fast animation using a latent consistency model

Projection module trained to add vision capabilties to Llama 3 using SigLIP

A fine-tuned SDXL based on GTA V art

Facebook Mask2Former trained on ADE 20k Dataset

Generate high-quality images faster with Latent Consistency Models (LCM), a novel approach that distills the original model, reducing the steps required from 25-50 to just 4-8 in Stable Diffusion (SDXL) image generation.

This is a tutorial example, where I take `nitrosocke/Ghibli-Diffusion` diffusion model and generate Van Gogh Paintings.

hello world
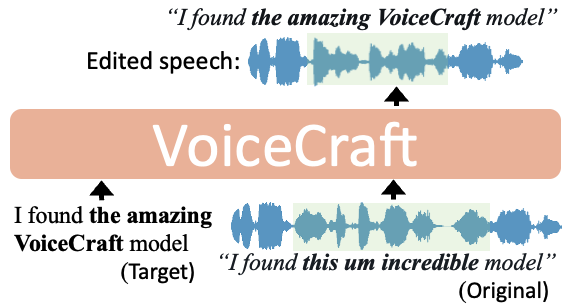
Zero-Shot Speech Editing and Text-to-Speech in the Wild

Fast video2video with a latent consistency model

Modify images using line art

Trained on old Looney tune RoadRunner background art

Fashion model
