
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text

Generate a collection of logos based on your text input. Use longer and more detailed inputs for better results. The first time it takes a few minutes to load the model. Subsequent generations are much faster.

Model trained on Family Guy animation style

Blip 3 / XGen-MM, Answers questions about images ({blip3,xgen-mm}-phi3-mini-base-r-v1)

Practicing Model Scaling for Photo-Realistic Image Restoration In the Wild. This version uses LLaVA-13b for captioning.

Generate an image using text by visualizing CLIP features.
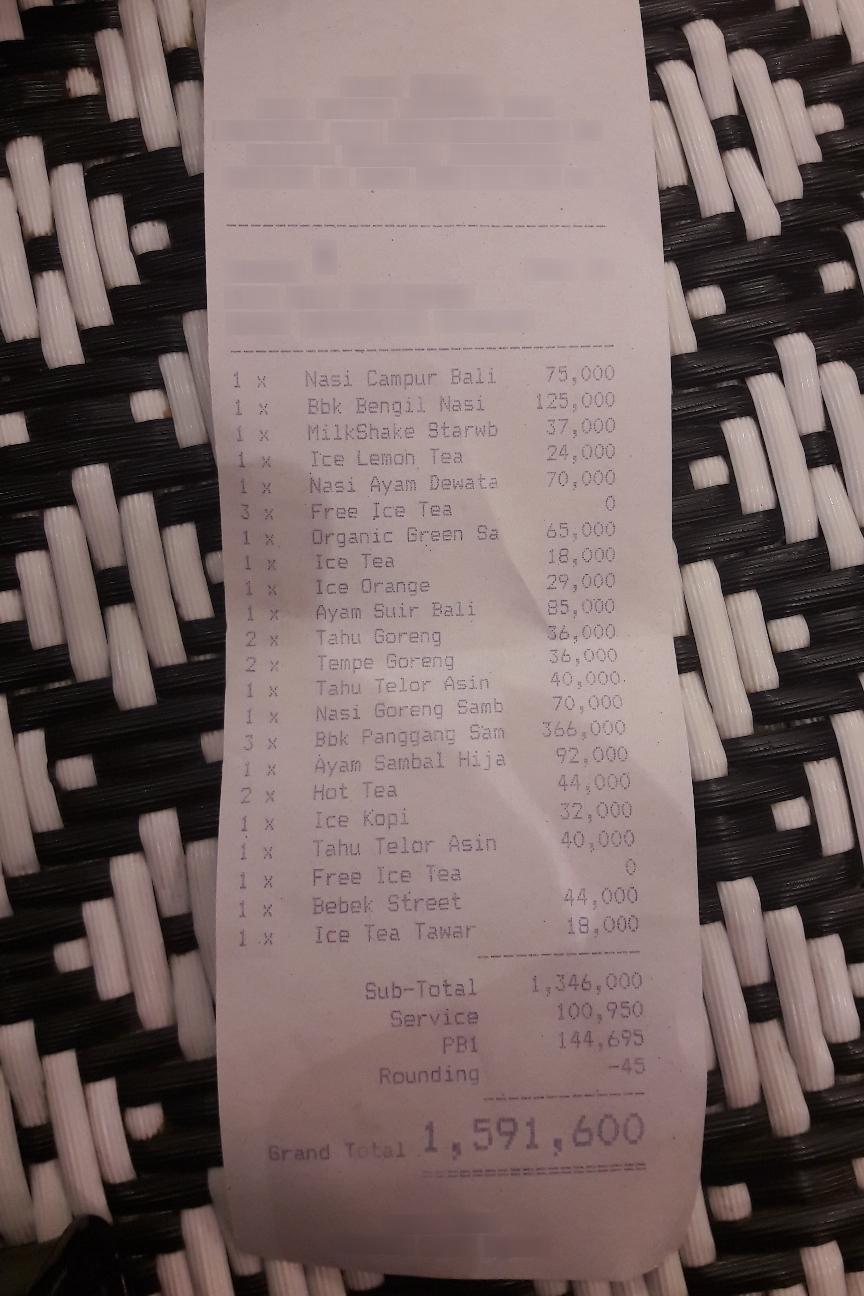
OCR receipt into JSON

a cat lora model

Visual instruction tuning towards large language and vision models with GPT-4 level capabilities

Deep Flexible Structure-preserving Image Smoothing

HairFastGAN: Realistic and Robust Hair Transfer with a Fast Encoder-Based Approach

A multi-input ControlNet model. Pass in control images and set the weights.

dreambooth trained on a very diverse dataset ranging from photographs to paintings

Source: kaist-ai/prometheus-13b-v1.0 ✦ Quant: TheBloke/prometheus-13B-v1.0-AWQ ✦ An alternative to GPT-4 when evaluating LLMs & Reward models for RLHF

Prompt-free Diffusion

Mistral-7B-v0.1 fine tuned for chat with the OpenOrca dataset.

Stable Diffusion XL fine-tuned to create images based on Le Corbusier's architectural style.

Photorealism with RealVisXL V4.0 Lightning

test api

Gunslingers backgrounds and possibly characters
