
Virtual try-on using Stable Diffusion and IP-Adapter

Text-Driven Manipulation of StyleGAN Imagery

Generate anime-style image

mixed stable diffusion model

PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding

Generate t-shirt logos with stable-dfffusion

Anything V4.5 Model (Text2Img, Img2Img and Inpainting)
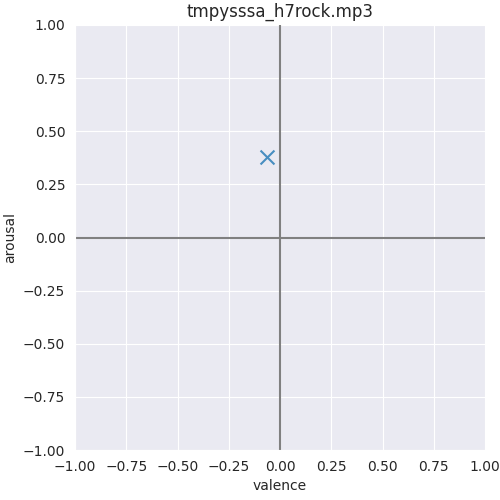
Regression of musical arousal and valence values

Source: SciPhi/Sensei-7B-V1 ✦ Quant: TheBloke/Sensei-7B-V1-AWQ ✦ Sensei is specialized in performing RAG over detailed web search results

Image Segmentation with DeepLabv3
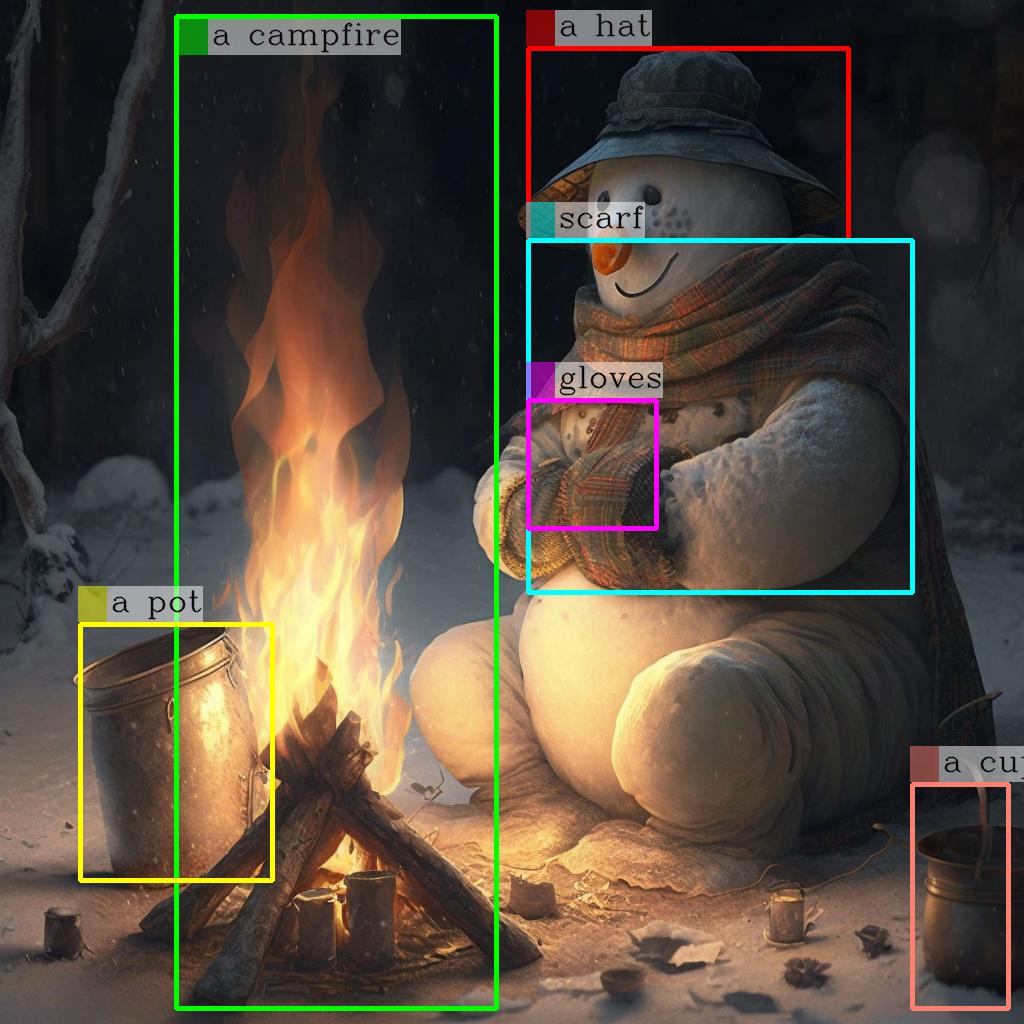
Grounding Multimodal Large Language Models to the World
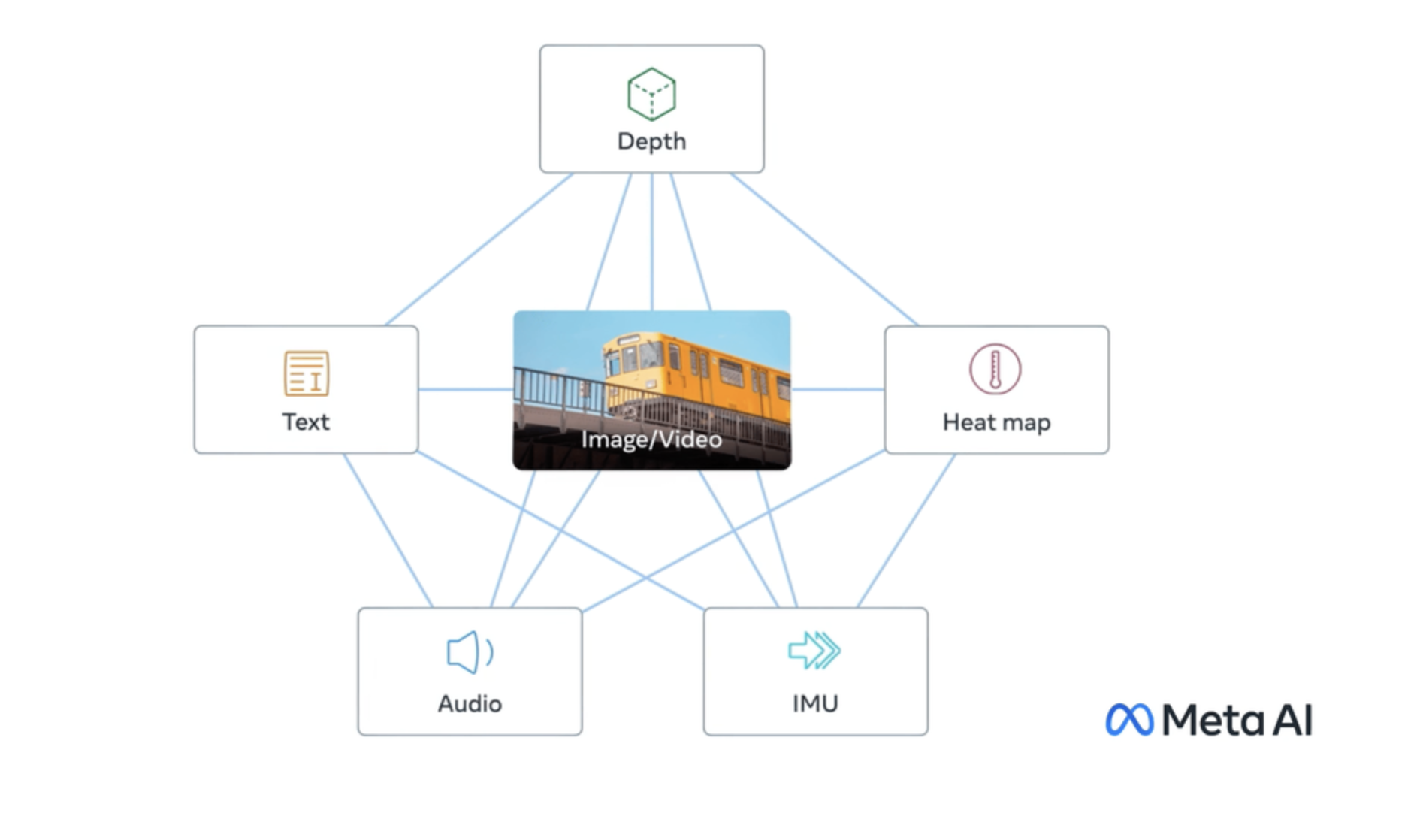
A model for text, audio, and image embeddings in one space

PyTSMod is an open-source library for Time-Scale Modification(eg. time-stretching) algorithms, by Sangeon Yong at MAC Lab, KAIST.

Change voice for spoken text

Realistic Inpainting with ControlNET (M-LSD + SEG)

StableDiffusion 1.4 + T2IAdapter (ControlNet) with style and openpose adapters + two upscaling passes with Real-ESRGAN

AI generated Normal maps, Displacement maps, and Roughness maps

Japanese-specific latent text-to-image diffusion model

🦙 LaMa Image Inpainting, Resolution-robust Large Mask Inpainting with Fourier Convolutions, WACV 2022

highist resolutioin image
