
stable-diffusion with v1-5 checkpoint

SDXL ControlNet - Depth

Depth estimation with faster inference speed, fewer parameters, and higher depth accuracy.
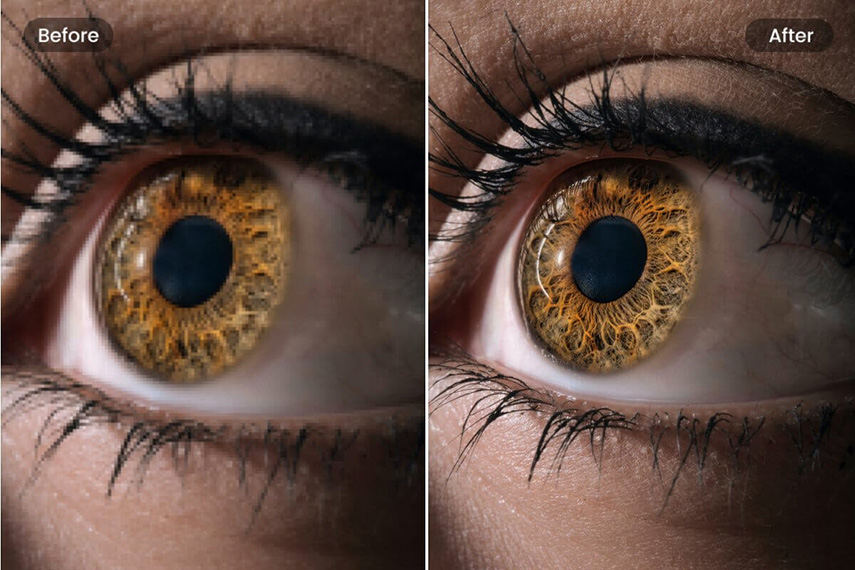
GFPGAN for human face video upscaling

Create your own variants of "this is fine" 🔥☕️🐕

Instance-Conditioned GAN

Modify images using canny edges

high-quality, highly detailed anime style stable-diffusion with better VAE

VideoCrafter2: Text-to-Video and Image-to-Video Generation and Editing
an autocomplete api that runs on the cpu :)

Remove images background

The online demo of Bread (Low-light Image Enhancement via Breaking Down the Darkness). This demo is developed to enhance images with poor/irregular illumination and annoying noises.

The predecessor to DALLE-2, GLIDE (filtered) with faster PRK/PLMS sampling.

Image restoration and face enhancement

(Research only) Moondream1 is a vision language model that performs on par with models twice its size

Use Huggingface model name to test a ANY diffuser model

fine-tuned Stable Diffusion model trained on the game art from Elden Ring

ChatGLM2-6B: An Open Bilingual Chat LLM | 开源双语对话语言模型
Generate Arab Maqam Melodic Improvisations (Taqasim)

Nous Hermes 2 - Yi-34B is a state of the art Yi Fine-tune, fine tuned on GPT-4 generated synthetic data
